Cool features of C++11
Published on 2018-04-23
The C++ programming language, as well as other popular programming languages, often get new functionalities and features. In this post, we will introduce several useful features from version C++11 of the C++ language, which is already supported by all significant compilers and integrated development environments. These features will help us write better code and avoid some of the problems that were part of the C++ language in its previous versions.
Setup Code::Blocks
By default, older versions of Code::Blocks use an outdated version of the C++ programming language, even if a compiler supports some C++11 features. To enable these new features, we need to make some changes:
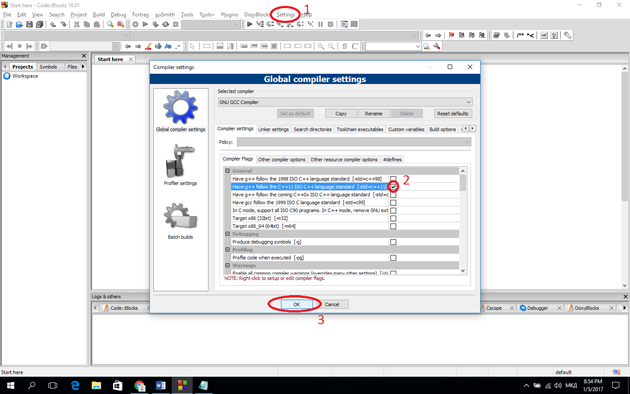
- When we start Code::Blocks, from the top menu (where you can see the buttons File, Edit, View, Search, etc.), select Settings, and then Compiler.
- In the newly opened window, tick the following option: "Have g++ follow the C++11 ISO C++ language standard" (or C++14/C++17, if you can see that)
- Click the OK button at the bottom of the window. (If you can not find these settings, download a newer version of Code::Blocks by searching for one on Google)
If you're stuck, look at the following image (and the steps highlighted there).
Simple initialization
In C++ you can create pairs with the make_pair() function. In addition, C++ supports a lot of data structures through the use of STL and containers.
In newer versions of the C++ programming language, we can create pairs by simply providing the necessary values inside brackets - { and }. Additionally, we can use the same functionality to create sets, lists, vectors and the like. More specifically, all these examples are valid:
pair<int, int> coordinates = {3, 5};
vector<int> v = {1, 2, 3, 4, 5};
set<int> s = {1, 2, 3, 4, 5};
This feature is also used in some of the example programs provided below.
Easy loops
In addition to the methods of defining loops that are already known to you, in C++11 there is an additional method to iterate (move) through container elements. We can do this by writing the for loop a bit differently. Namely, this time, we use the data type of the elements in the container, but we also choose a name for one variable that will hold the element values (or references to them) - without needing to define anything else. For a vector of integers called "numbers", we can write something like this:
for(int x : numbers){
cout << x << endl;
}
This code will print all the elements found in the vector. We can write for loops for vectors, lists, sets, and more. For maps, we have to make sure that our variable has the data type pair<>, where the first element of the pair will store the key, while the second element will store the value. Let's take a look at the following program:
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main()
{
map<int, string> names;
names[0] = "Mark";
names[1] = "James";
names[2] = "Trump";
for(pair<int, string> value : names)
{
cout << value.first << ": " << value.second << endl;
}
//0: Mark
//1: James
//2: Trump
return 0;
}
In the example given above, the comments reveal the program's output. Interestingly, apart from moving through dynamic-sized containers by pointing to the element values, we can also change the values themselves. We can do this by simply using a reference to the element itself, with the help of the & operator. For example, the following code will increase the values of all elements by 1.
for (int &x: numbers){
x++;
}
The keyword "auto"
In the previous program, it kind of looks unnecessary to write that the variable in the for loop has the data type pair<int, string>. By looking at how the map is defined previously, we would expect that the computer should be "smart" enough to determine the data type automatically. Can this be done? Yes. In recent versions of the C++ programming language, there is no need to specify the correct data type everywhere, if there is a way for the computer to detect it automatically. For example, we can replace the statement:
for (pair<int, string> value : names)
with
for (auto value : names)
The program will still compile and work. However, note that auto can't be used everywhere - for example, it can not be used to define the data structures (containers) themselves, such as vector<auto> v. That actually makes sense, since in the beginning of our programs, the system doesn't know what data you want to store.
Iterators
This part of the post will be a bit more complex, but it is important in order to fully understand all the functionality of the Standard Template Library. I'm sure that you've already used some algorithms that are part of STL (like "sort"), and every time you call them, you probably also use the methods begin() and end(). For example, to sort all elements in a vector called "numbers", we can write something like this:
sort(numbers.begin(), numbers.end());
These two methods begin() and end() can be applied to various containers (sets, maps, lists, etc.) and they always return appropriate pointers that indicate the beginning and the end of (those) containers. In other words, begin() points to the first element, while end() points immediately after the last element (ie, end() - 1 points to the last element). Note that begin() and end() return pointers (not values), so in order to get the actual value, we need to use the operator *, for example *numbers.begin(). Specifically, since these methods are implemented for multiple containers, with the instructions given below, we can print the first and last element of either a vector, a list, a set, or something else:
auto first = numbers.begin();
auto last = --numbers.end();
cout << *first << endl;
cout << *last << endl;
Something else that is really cool is that set<> uses a binary tree to store elements, so begin() points to the smallest element (by value), while end() - 1 points to the largest element.
Here, it's time to mention the exact terminology used in the Standard Template Library. Namely, the structures in which we store values are called containers (vector, list, set, map, etc.), while the pointers are called iterators (actually, iterators are a generalization of pointers, so all pointers to objects are iterators). So, in the Standard Template Library, we're talking about containers and iterators.
Getting acquainted with iterators gives us the opportunity to mention two more features that are useful with binary trees (for example, set <> and map <>). Specifically, sometimes we want to find the first element greater than a given value. With binary trees, this operation has logarithmic time complexity O(logN), which means that it is very efficient. We can use the functions lower_bound(K) to get a pointer to the first element greater than or equal to K, and upper_bound(K) to get the first element greater than K (but not equal). This is presented in the following program. Please, notice how certain problems can be solved efficiently by simply using the correct data structure.
#include <iostream>
#include <set>
using namespace std;
int main()
{
set<char> letters = {'A', 'B', 'C', 'D', 'E'};
auto bigger_or_equal = letters.lower_bound('C');
cout << *bigger_or_equal << endl; //'C'
auto strictly_bigger = letters.upper_bound('C');
cout << *strictly_bigger << endl; //'D'
return 0;
}
Binary trees are extremely powerful. Knowing their advantages and features, and when they can be applied, will make you a much better programmer.
Hash tables
Starting with C++11, the Standard Template Library offers the ability to use hash tables without any special flags or importing strange libraries. In addition, the containers themselves have very similar names to those introduced for sets and maps (the ones where data is stored in binary trees). Specifically, to use a hash table to store values in a set we can call upon unordered_set<>, while to use a hash table to store values in a map we can call upon unordered_map<>. In addition, method names are same as before. For unordered_set<>, we can find the number of elements with size(), add a new element with insert(), delete an element with erase(), and check whether an element exists with count(). All these operations have constant complexity O(1). Because elements are organized differently in hash tables, we can not effectively find the smallest or largest element, or use functions like lower_bound() and upper_bound() - in those cases, it is better to use set<> (i.e. binary trees). In situations where we only want to add, delete and query elements, a hash table is a perfect choice.
Similar to map<>, with unordered_map<> we can use the operator [] to add, modify or read values. The time complexity is O(1).
#include <iostream>
#include <unordered_set>
#include <unordered_map>
#include <vector>
using namespace std;
int main()
{
vector<int> numbers = {1, 2, 3, 4, 5, 1, 2, 3, 4, 5};
unordered_set<int> different;
unordered_map<int, int> occurrences;
for(auto number : numbers)
{
different.insert(number);
occurrences[number]++;
}
//different = [1, 2, 3, 4, 5]
cout << different.size() << endl; //5
//occurrences[1] = 2, occurrences[2] = 2, ...
cout << occurrences[1] << endl; //2
return 0;
}
Please note that, at the beginning of the program, we use #include <unordered_set> and #include <unordered_map>. Without these lines, we can not use the new containers.
Sorting by different criteria
As we mentioned before, the STL contains several algorithms that can be applied to various data structures. One of them is the algorithm that allows us to sort elements in a vector.
Usually, when sorting, elements are ordered from smallest to largest (in the case of integers or floating-point numbers), or alphabetically (for strings). When we say "alphabetically", we mean sorting like in a telephone directory, or a dictionary - where words beginning with A are found first, etc. When we call sort() on a vector of strings, we will first get all words that start with capital letters, and then all words that start with lower case letters. So, if we have the following vector:
vector<string> names = { "beta", "alpha", "Delta", "Sigma" }
after sorting, we will get the vector: {"Delta", "Sigma", "alpha", "beta"}, where all words starting with an upper case letter are sorted correctly ("Delta" comes before "Sigma"), and all words that start with a lower case letter are also sorted correctly. However, due to the fact that all uppercase letters are placed before all lowercase letters (comparison is initially done on the first letter, then on the second, etc), the ordering may not be as we would expect.
That being said, there is a way to define a different sorting criteria. Until C++11, this was done by creating a new function as presented below. Please note that we can iterate (with a for loop) each character of a string (because they are elements of a container).
#include <iostream>
#include <vector>
#include <string>
#include <algorithm>
using namespace std;
int compare_lowercase(string a, string b)
{
string lowercase_a = a;
for(char &ch : lowercase_a)
ch = tolower(ch);
string lowercase_b = b;
for(char &ch : lowercase_b)
ch = tolower(ch);
return (lowercase_a < lowercase_b);
}
int main()
{
vector<string> names = { "beta", "alpha", "Delta", "Sigma" };
sort(names.begin(), names.end(), compare_lowercase);
for (auto name : names)
{
cout << name << endl;
}
return 0;
}
In the program above, we have a function compare_lowercase, which makes copies of the strings that arrive as arguments (so the code is easier to read). Therefore, in lowercase_a we have a copy of a, but composed of lowercase letters only. We do likewise with lowercase_b. For sorting to work correctly, our compare_lowercase function should compare both arguments and return a value that indicates whether the elements are in correct order. In other words, our function returns true if a should come before b - which we check by comparing their lowercase letter variants (i.e. lowercase_a < lowercase_b).
Finally, let's see how this program would look like if we want to write it in C++11. Specifically, what if we don't like to create a new function on the top? Instead, with C++11, we can use lambda expressions and do the comparison in the same place where we call the sorting algorithm. It will look like this:
vector<string> names = { "beta", "alpha", "Delta", "Sigma" };
sort(names.begin(), names.end(), [&] (string a, string b) -> bool
{
string lowercase_a = a;
for(char &ch : lowercase_a)
ch = tolower(ch);
string lowercase_b = b;
for(char &ch : lowercase_b)
ch = tolower(ch);
return (lowercase_a < lowercase_b);
});
In my opinion, this doesn't look that pretty, especially when we have complex comparison functions. For now, you can decide for yourself whether you prefer to define your own function above the call, or use lambda expressions. Some developer teams use lambda expressions often, and some avoid them.
At the end of this post, note that you will almost always write simpler comparison functions - in one or two lines. In this post, I wanted to use a specific example where the strings can contain both uppercase and lowercase letters (because that is an interesting and challenging problem in itself). By comparison, this is all you have to do in order to sort numbers in descending order (from largest to smallest):
vector<int> numbers = {1, 5, 7, 2, 6};
sort(numbers.begin(), numbers.end(), [&] (int a, int b) -> bool
{
return (a > b);
});
After running this code, "numbers" will look like this: {7, 6, 5, 2, 1}. As another example, this is all you have to do in order to sort a vector of strings by their length (so strings that have less characters come first):
vector<string> names = {"james", "ema", "john"};
sort(names.begin(), names.end(), [&] (string a, string b) -> bool
{
return (a.size() < b.size());
});
After the sort() call, we get {"ema", "john", "james"}, because "ema" consists of 3 characters, "john" of 4 characters, and "james" of 5 characters.
A cool #include directive
In all programs written so far, we had to add multiple #include <...> directives (in order to use containers, algorithms, etc). Interestingly, all these programs will work the same if we replace all #include <...> directives with just this one: #include <bits/stdc++.h>. For example, this is a valid C++ program:
#include <bits/stdc++.h>
using namespace std;
int main()
{
vector<int> v = {10, 5, 7};
sort(v.begin(), v.end());
for(auto number : v)
{
cout << number << endl;
}
return 0;
}
However, since <bits/stdc++.h> is not part of the C++ standard, there is a chance to get errors when compiling these programs - especially if we use a different development environment or compiler (gcc supports it, but some other compiler might not). Nevertheless, I wanted to mention this option because it is useful when writing simple programs and running them on your computer.
