Disjoint-set data structure
Published on 2018-05-10
Many processes and events involve examining sets of elements and performing operations on them - such as joining the sets or discovering whether two elements belong to the same set or not. For example, we can talk about sets of objects, sets of individuals, sets of locations (checking that they belong to the same owner, or buying and thus uniting multiple locations that previously belonged to different individuals), etc.
In addition, this post will discuss a structure that allows us to perform two operations: joining sets, and discovering the location where a particular element belongs (thus, for example, we can determine if two elements belong to the same set or not). We will mostly focus our discussion around vertices (and graphs), but the structure we will describe can be applied to any category of sets. However, by looking at the elements as if they are vertices that belong to a graph, it will be much easier for us to understand the general idea, as the sets themselves can be easily presented visually.
Implementation
Let's say that we have N elements, and that all of them belong to different sets - that is, we have N sets, where each set has only one element. These sets can represent people, objects, etc. The data structure that we will see in this post (and the algorithms that we will perform on it) enables us to merge these sets (using a function called Union), as well as to find out whether two elements belong to the same set (using a function called Find).
Specifically, if each element (vertex) holds one value that indicates its leader; and we want to find out which set the element belongs to, then either the element can "tell us" itself (if it is the leading element in the set), or it will know (recursively) to ask "it's leader". This is the main idea of the disjoint-set data structure, and the algorithms that apply there (union-find). Below, we will try to make these algorithms more efficient - so that they work in near-constant time O(1).
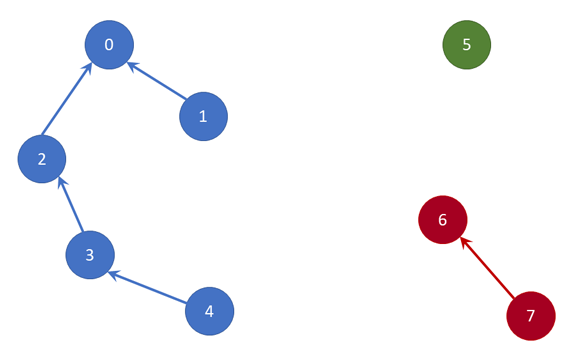
As you can see from the picture above (where three sets are represented), connecting or joining two sets into one (Union) is done by simply adding a new link from one element (from the first set) to another element (from the second set). Practically, this means that we simply need to indicate that the new leader of an element of one set is the element of the other set. Please, notice that most of the elements in the picture above have leaders, but some don't have such a thing. For these elements we say that they are the main leader in the set (or "root", because the structure resembles a forest - i.e. set of trees).
Okay, but how do we know if two elements belong to the same set? This is actually very simple. Specifically, the only thing that's necessary for us to identify is the main leader in the set of the first element, and the main leader in the set of the second element. If they are equal (i.e. the sets have the same root), then those two elements belong to the same set. In other words, our goal is to implement a function Find(X), which for a given element X will return the main leader in the set where X belongs to. If we can do this, it will be very simple to check whether two elements X and Y already belong to the same set, using the condition Find(X) == Find(Y).
Before we move on, let's see how we can improve this algorithm so that it will be much more efficient. Namely, we will do two improvements - one for finding a leader, and another one for merging. For Find(), we already mentioned that we need to find the main leader in the set. But the element where we start from can have a leader who is not the root of the set, so we need to recursively move up the tree until we reach the main leader (practically, we search for the leader of the first element, then for the leader of that leader, etc.). The first improvement that we will do is the following: when someone calls the Find(X) function, and the algorithm recursively finds who is the main leader in the set where X belongs, then before returning the result, we will store (write in memory) that the new leader of X is the root of the set. This has two positive impacts. Specifically, at the next call to Find(X), there will be less/no recursive calls, because the leader of X is the root of the set, so the algorithm will end faster. Similarly, all the elements which have X as their leader (let Y be one of them), will now be able to get to the main leader in the set much faster as they need to recursively go through just two levels Y -> X -> main leader.
As we have indicated before, the second improvement is done during merging. To be more precise, we will store one more value for an element that will indicate its "rank". Specifically, the goal that we want to achieve with this data is speed up the merging when examining the main leader of one set and the main leader of the other set, and make sure that we point the new link so that it goes from the leader with the lower rank to the leader with the higher rank. If we do that, the rank will actually indicate the length of the largest path in the tree (if you see the structure and the links in it, each set resembles a tree). In other words, we connect the smaller tree to the larger tree. Since we connect the main leader of one tree with the main leader of another tree, the result will be a tree where the length will be either equal (if one tree is smaller), or will increase by 1 (if the trees were of equal length). Length will increase by 1 because, besides the current length, there will now be another link (from the first leader to the second).
The implementation of what we discussed so far is given below.
#include <iostream>
#include <cstring>
using namespace std;
int leader[101];
int ranking[101];
int Find(int X)
{
if (leader[X] != X)
{
int setLeader = Find(leader[X]); //ask leader[X]
//remember the result (improvement)
leader[X] = setLeader;
}
return leader[X];
}
void Union(int X, int Y)
{
int setLeaderX = Find(X);
int setLeaderY = Find(Y);
if (setLeaderX == setLeaderY)
{
return /* already in the same set */;
}
if (ranking[setLeaderX] == ranking[setLeaderY])
{
//same rank, so choose one
leader[setLeaderY] = setLeaderX;
//the rank will increase
ranking[setLeaderX]++;
}
else
{
//different rank, so connect to the larger tree (without updating ranking[])
if (ranking[setLeaderX] > ranking[setLeaderY])
{
leader[setLeaderY] = setLeaderX;
}
else
{
leader[setLeaderX] = setLeaderY;
}
}
}
int main()
{
int N = 5;
for (int i=0; i<N; i++)
{
//initially, all belong to a different set
leader[i] = i;
}
//initially, everyone get's a rank of 0
memset(ranking, 0, sizeof(ranking));
//let's do a couple of operations
if (Find(0) != Find(1))
{
//this will get printed
cout << "0 and 1 are in different sets." << endl;
}
Union(0, 1);
if (Find(0) == Find(1))
{
//this will get printed
cout << "Now, 0 and 1 are in the same set." << endl;
}
if (Find(0) != Find(2))
{
//this will get printed
cout << "0 and 2 are in different sets." << endl;
}
Union(2, 3);
Union(2, 4);
//here, we have two sets [0, 1], and [2, 3, 4]
if (Find(0) != Find(2))
{
//this will get printed
cout << "0 and 2 are in different sets." << endl;
}
Union(0, 4);
//here, we have just one set [0, 1, 2, 3, 4]
if (Find(0) == Find(3))
{
//this will get printed
cout << "0 and 3 are in the same set." << endl;
}
return 0;
}
Note that this structure does not allow us to delete links, or break up one set into multiple "smaller" sets.
Examples
Of course, the data structure we implemented can be used to solve various problems related to sets - especially when the main operation is merging. Next, we will consider two examples in order to better understand the huge potential of the disjoint-set data structure.
First, let's begin by looking at an undirected graph, where we have vertices that are interconnected by edges. Since the graph is undirected, if there is a path between two vertices (direct, or through multiple edges), then there is a path in the reverse direction. In these types of situations, we can use the disjoint-set data structure to check whether adding a new edge to the graph will result in a new cycle. Specifically, when examining an edge before calling the function Union(), we should just check if the two vertices (that the edge connects) are already part of the same set or not (whether Find(X) == Find(Y)). If they are already in the same set, then there is a path between them, and adding a new edge will cause the creation of a new cycle. (Note that this applies only to undirected graphs).
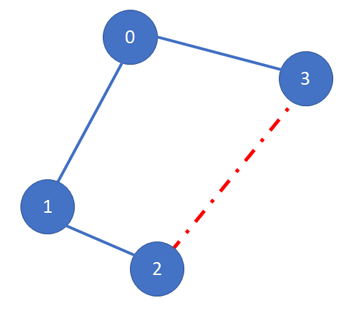
You can also see this from the image given above. Specifically, if we add the edge colored in red, a new cycle will appear in the graph. In order to identify the problem before adding the edge, we should just use the structure that was discussed in the previous section.
The second example that we will consider is actually an algorithm for creating a minimum spanning tree. If you recall, a spanning tree is a tree that contains all the vertices of an undirected graph, but only some of the edges - i.e. those needed in order for all vertices to be connected. (Logically, there are no cycles in a spanning tree). A minimum spanning tree is a spanning tree where the sum of edge weights is minimal. In other words, since there can be several spanning trees connecting the vertices (especially when there are a large number of edges in the graph), we are usually interested only in the spanning tree with the lowest sum of weights. One algorithm for finding a minimum spanning tree (MST) is called Prim. The implementation of the Prim algorithm is very similar to Dijkstra (which is used to find a shortest path), and is based on the idea that we can start from one vertex, and then keep adding new vertices (one after another), by starting with those that are closest to the tree.
Kruskal is another algorithm that we can use to discover a minimum spanning tree. To implement it, we need to use the disjoint-set data structure that was introduced in this post. Specifically, the Kruskal algorithm (unlike Prim), examines all edges (one by one) of the initial graph, by starting with those edges that have the smallest weight. When a new edge is considered, the decision whether to add it to the minimum spanning tree will depend (only) on whether or not the two vertices (that the edge connects) are already in the same set or not. If they are not in the same set, then the new edge will be added to the spanning tree, and we will merge the two sets. Of course, since we need to look at the edges starting from the one with the smallest weight (and then the one with the second smallest weight, etc), we will sort the edges in ascending order of their weight. The implementation of the functions Union() and Find() will remain unchanged.
#include <iostream>
#include <vector>
#include <cstring>
#include <algorithm>
using namespace std;
//the initial graph
int N;
vector<pair<int, int> > G[101];
//union-find
int leader[101];
int ranking[101];
int Find(int X)
{
if (leader[X] != X)
{
int setLeader = Find(leader[X]);
leader[X] = setLeader;
}
return leader[X];
}
void Union(int X, int Y)
{
int setLeaderX = Find(X);
int setLeaderY = Find(Y);
if (setLeaderX == setLeaderY)
{
return /* already in the same set */;
}
if (ranking[setLeaderX] == ranking[setLeaderY])
{
leader[setLeaderY] = setLeaderX;
ranking[setLeaderX]++;
}
else
{
if (ranking[setLeaderX] > ranking[setLeaderY])
{
leader[setLeaderY] = setLeaderX;
}
else
{
leader[setLeaderX] = setLeaderY;
}
}
}
//a separate structure, so we can add the edges in a vector
//and then sort them by weight
struct Edge
{
int from, to, weight;
};
int kruskal()
{
//initialize leader and ranking
for (int i=0; i<N; i++)
{
leader[i] = i; //every vertex is in a separate set
}
memset(ranking, 0, sizeof(ranking));
//create a list of all edges, so we can sort them
vector<Edge> edges;
for (int i=0; i<N; i++)
{
for (auto next : G[i])
{
Edge edge;
edge.from = i;
edge.to = next.first;
edge.weight = next.second;
edges.push_back(edge);
}
}
sort(edges.begin(), edges.end(), [](const Edge a, const Edge b) -> bool
{
return a.weight < b.weight;
});
//iterate through all edges (starting from the ones with the smallest weight)
int totalEdgeWeight = 0;
for (auto edge : edges)
{
if (Find(edge.from) != Find(edge.to))
{
//the vertices are in different sets
Union(edge.from, edge.to);
totalEdgeWeight += edge.weight;
}
}
return totalEdgeWeight;
}
int main()
{
N = 5;
G[0].push_back({1, 5}); //edge from 0 to 1, with weight 5
G[1].push_back({0, 5}); //the graph is undirected, so add the reverse edge
G[0].push_back({3, 7}); //edge from 0 to 3 with weight 7
G[3].push_back({0, 7}); //the graph is undirected, so add the reverse edge
G[0].push_back({4, 1}); //edge from 0 to 4 with weight 1
G[4].push_back({0, 1}); //the graph is undirected, so add the reverse edge
G[3].push_back({4, 2}); //edge from 3 to 4 with weight 2
G[4].push_back({3, 2}); //the graph is undirected, so add the reverse edge
G[4].push_back({2, 9}); //edge from 4 to 2 with weight 9
G[2].push_back({4, 9}); //the graph is undirected, so add the reverse edge
int result = kruskal();
cout << "Minimum spanning tree has a total weight of " << result << endl;
return 0;
}
Of course, both algorithms (Prim and Kruskal) always arrive at the correct result. It's up to you to decide which one is simpler for you to implement, and which one you will use to solve a particular problem. Personally, the author of this blog is using Prim's algorithm more often, since it is very similar to Dijkstra. In this post, we decided to mention the Kruskal algorithm as an example of the power of the disjoint-set data structure, and see how the functions Union() and Find() can be implemented in practice.
